For the Best Experience - It is highly recommended browsing this blog on a desktop or laptop computer for the most optimized viewing experience. Enjoy exploring!
Language Detection & Sentiment Analysis with Local LLMs
In this post we will work on how to automate tasks such as language detection and sentiment analysis with R using an LLM on the local computer.
I have recently received an e-mail from Posit about their recent developments. They have released the BETA version of their new IDE, Positron, for data scientists along with several R packages and a chat bot customized for shiny apps, Shiny Assistant. The packages are elmer, pal, and mall. Today, we will try mall with a local LLM to automate several tasks and run a sentiment analysis.
A few years ago, running an LLM locally would be a dream for most of the data scientists. However, with the recent developments in the field, there are many free-to-use LLMs that can be run on your local machine. I am choosing my words carefully here. Since Meta released llama, they advertise it as open-source. Yet, it is not open-source in the sense that you can see the algorithm behind it or/and the data used to train it. It is open-source in the sense that you can use it for free. In this regard, it is more of a free-to-use tool than an open-source tool. However, I should also appreciate the effort behind it as we can use a strong LLM freely on our local computers.
Getting Started
Enough of politics. Let’s get started by downloading ollama to our local machine.
Download Ollama
Ollama is an open-source LLM service tool that helps users to utilize LLMs locally with a single line of command. You can download it from here depending on your operating system. Yet, I will run you through Windows rather than Linux or MacOS.
Click Windows on the download page and then click the download button. Once the download is complete, open the downloaded installer. As far as I remember, the installer completes without any prompting.
Before we use R, we need to set some basics. A local LLM is highly dependent on your hardware. You need a good CPU, RAM, and VRAM to run it. Today, I will use llama3.1 8b. 8b in the model name refers to the number of parameters that the model is trained with. The more parameters, the more accurate the model. However, the more parameters, the more hardware you need.
Requirements for llama3.1 8b
CPU >= 8 cores
RAM >= 16 GB
VRAM >= 8GB
NVIDIA RTX 3070 or better
If you do not have sufficient hardware, you can use a smaller model such as llama3.2 which comes with 1b and 3b. Gemma:2b is also a viable option. If you have even a better computer, you can try other models with higher parameters. You can see the list of all available models here.
Install the Model
There are many ways to install the model. We will discuss two here. You can either use the terminal or mall package in R. My personal preference is to use the terminal as we will need to terminate ollama to end the memory usage when we are done. However, if you are not familiar with the terminal, you can use R.
Install the Model on the Terminal
Once you have decided on your model, open a terminal. You can do that by searching for Windows PowerShell and running it. If you are Rstudio user, you can also open a terminal in Rstudio. They will both work for our use case.
On the terminal, type the following command with the model name of your preference. ollama run <model name>
ollama run llama3.1:8b
This will install the model to your computer, if it is not installed already, and then it will start a chat session with the model. You can chat with the bot on the terminal directly. To end the session, simply type /bye or CTRL + C.
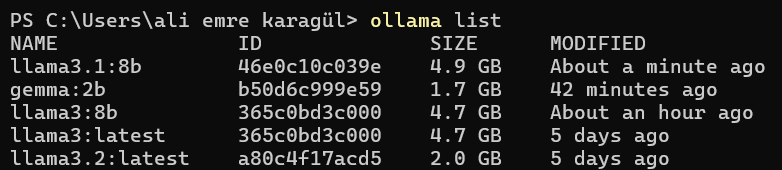
You can install as many models as you like as long as your hardware allows. To see all the models that you have installed so far, run ollama list command on the terminal.
Install the Model via R
To install a model via R, you need to load the mall package. In the mall package, pull("<model name>") function is used to install a model. test_connection() is used to see if your local LLM up and running.
list_models() is used to see the models that you have installed so far. That one is more informative than the terminal command as it gives us the parameter size and the quantization level too.
You can also test the model by giving a prompt. The generate function is used to generate a response from the model.
ollamar::generate(model_name, "Tell me a joke about statistics.", output ="text")
[1] "Here's one:\n\nWhy did the statistician turn down the invitation to the party?\n\nBecause he already had a 99% probability of being bored and a 1% chance of meeting interesting people.\n\nHope that made you laugh!"
Task Automation
If you have come so far, you are ready to use your local LLMs for anything. Let’s see some example usage.
Language Detection
Most LLMs are multi-lingual. You can use them to detect the language of a given text such as a comment or a review. Let’s build such an automation. We will use a dataset of global comments from YouTube videos on Kaggle. You can download the csv file directly from my Google drive too.
Preparing the Data
The data is too large, so in this part, we will investigate and select a subset of 20 rows that contain multiple languages, emojis, urls etc. We will then detect the language of each comment in the subset using our local LLM.
We will be using packages such as dplyr, stringr, tidyverse, and purrr to manipulate the data. Also mall package, having very useful functions such as llm_sentiment(), llm_classify(), llm_extract(), llm_custom() etc, will be used to interact with the LLM.
video_id comment_text likes replies
Length:273551 Length:273551 Length:273551 Length:273551
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
We need to change the class of likes and replies to numeric. Also, I have checked the data and detected many duplicate rows. So, we need to get rid of the duplicate data entries. Also let’s drop the rows with NA values.
global_comments$likes<-as.numeric(global_comments$likes)global_comments$replies<-as.numeric(global_comments$replies)# drop rows with the same comment text in the same videoglobal_comments<-global_comments%>%distinct(video_id, comment_text, .keep_all =TRUE)%>%drop_na()global_comments<-global_commentssummary(global_comments)
video_id comment_text likes replies
Length:152589 Length:152589 Min. : 0.00 Min. : 0.00
Class :character Class :character 1st Qu.: 0.00 1st Qu.: 0.00
Mode :character Mode :character Median : 0.00 Median : 0.00
Mean : 16.94 Mean : 13.95
3rd Qu.: 0.00 3rd Qu.: 0.00
Max. :60630.00 Max. :3498.00
We have 152589 rows of data. For the demonstration purposes, I will select a couple of videos with comments in multiple languages. There are many ways to detect videos with comments in multiple languages. My approach will be to search for specific strings in Korean, Arabic and German. For example, the first letter of “hello” in Korean is “한” according to Google Translate. Let’s search for this letter in the comments and select the video with the most comments. Also, utilize a similar approach for Arabic and German. Remember we are doing this to create the perfect subset of comments with multiple languages.
[1] "Marvelous, as Always!"
[2] "Bellisimo :3Saludos desde Mexico cdmx"
[3] "Pure! Serene! and Marvelous!"
[4] "So diverse. Much ethnic. Wow."
[5] "Enough said"
[6] "😘😘😘😱😱"
[7] "woow.. eres magnifica, por ti me apasione con el violin y compre el mio... soy tu mas grande admiradora, dios y algun dia me lo permita conocerte es mi mayor sueño y aprender a tocar el violin.. sigue triunfando y robando los carazones de las personas asi como me lo robaste a mi con tu melodia."
[8] "Cuando veniste a Guadalajara y escuche esta canción I couldnt believe it was just like no mames 😍😍😍"
[9] "man kann richtig sehen wie dir das Tanze und Violine spielen spass und freude macht. 👍\\n\\nSo macht das zuschauen nochmal so viel spass.\\n\\nSuper Video☺️👍"
[10] "Heisses Outfit , dass der Sound gut ist, ist ja schon bald selbstverständlich."
I can see many languages except for Korean and Arabic in the tail. :D Let’s select a random subset of this data to test our language detection bot.
# select random 20 comments.dat<-dat%>%sample_n(20)print(dat$comment_text)
[1] "YOU ARE SO CLOSE TO 10 MILLION!!!"
[2] "😍"
[3] "Also watch https://youtu.be/7QkYTgDMpCs"
[4] "I❤️U 💋💋💋💋💋💋💋💋💋😍😍😍😍😍😍😍😍😘😘😘😘😘😘😘😘😘💖💖💖💖💖💖💖💖😻😻😻😻😻😻👸👸👸👸👸👸💟💟💟💟💝💝💝💝💓💓💓💗💗💗💜💜💜💋💋💋👰👰👰"
[5] "Ya lo tengo y estoy escribiendo de acá del iPhone me anda de 10"
[6] "Amazing video I love the Bollywood touch in this video keep going Lindsey!!"
[7] "Where's iPhone 9? Just skips to iPhone x. Lol okay nice math there Apple"
[8] "عملت قنات جديدة تختص في تقديم أنجح و أسهل وصفات الحلويات، تعالو شوفو الفديوهات التي اعملها والله ما رح تندمو ❤"
[9] "Nothing new..\\nIphoneX is copy of essiential phone.\\nAndy Rubin has developed more advanced features than iPhoneX.\\nIPHONE X 👎👎👎"
[10] "Lol @22:46:09\\n\\nTim's kinda an ass"
[11] "3 years late on wireless charging, 3 years late on oled technology , old facial recognition tech enhanced by old IR tech. So your late on just about every front....what to do? I know, lets lose what makes our product instantly recognizable! This is Apples windows 8, Samsung are bound to be loving this."
[12] "https://youtu.be/Kp_DBWtS6SU"
[13] "I love your music videos their always great and inspiring!"
[14] "I like for Linsey. Love yours full themes. Great job."
[15] "I love that blond hair!!!!"
[16] "黒髪もも可愛すぎ😍💕💕"
[17] "Sana is my damn bias wrecker, i swear. between her and Nayeon it's so hard😂❤"
[18] "where is Steve Wozniak, fuck apple authority"
[19] "just one question, wtf?"
[20] "She is BEA-UTIFUL. And this showed a side I've never seen before. Which is not surprising. She's always giving us surprises....she keeps me in my toes"
Detecting languages
That subset looks good. I can see emojis, urls and multiple languages along with English. That’s a perfect subset to test the language detection capabilities of our LLM. Here is what we will do: 1. Attach the model with llm_use(). 2. Define a system prompt for language detection. 3. OPTIONAL: Define the valid responses that you expect from the LLM. If this is defined, any response that do not fit the valid responses will be replaced with NA. 4. Detect the language of each comment in the data and add the results as a new column.
llm_use("ollama", model_name, seed =100, .silent =TRUE)sys_prompt<-paste("You are a language detection bot.","I will provide you with Youtube comments on a video.","Try to detect the language of the comment and reply with the ISO 639-1 language code used in the given comment.","Reply only with the language code.","If you cannot detect a language as the comments might contain emojis or urls only, reply with 'UNDETECTABLE' with uppercase","Some examples:","comment text: 'Thumbs up asap', your response: 'en'.","comment text: 'Hola, ¿cómo estás?', your response: 'es'.", "Here is the comment:")# I am not adding 'UNDETECTABLE' to valid responses as the function will tag such cases as NA.valid_responses<-c("aa", "ab", "ae", "af", "ak", "am", "an", "ar-ae", "ar-bh", "ar-dz", "ar-eg", "ar-iq", "ar-jo", "ar-kw", "ar-lb", "ar-ly", "ar-ma", "ar-om", "ar-qa", "ar-sa", "ar-sy", "ar-tn", "ar-ye", "ar", "as", "av", "ay", "az", "ba", "be", "bg", "bh", "bi", "bm", "bn", "bo", "br", "bs", "ca", "ce", "ch", "co", "cr", "cs", "cu", "cv", "cy", "da", "de-at", "de-ch", "de-de", "de-li", "de-lu", "de", "div", "dv", "dz", "ee", "el", "en-au", "en-bz", "en-ca", "en-cb", "en-gb", "en-ie", "en-jm", "en-nz", "en-ph", "en-tt", "en-us", "en-za", "en-zw", "en", "eo", "es-ar", "es-bo", "es-cl", "es-co", "es-cr", "es-do", "es-ec", "es-es", "es-gt", "es-hn", "es-mx", "es-ni", "es-pa", "es-pe", "es-pr", "es-py", "es-sv", "es-us", "es-uy", "es-ve", "es", "et", "eu", "fa", "ff", "fi", "fj", "fo", "fr-be", "fr-ca", "fr-ch", "fr-fr", "fr-lu", "fr-mc", "fr", "fy", "ga", "gd", "gl", "gn", "gu", "gv", "ha", "he", "hi", "ho", "hr-ba", "hr-hr", "hr", "ht", "hu", "hy", "hz", "ia", "id", "ie", "ig", "ii", "ik", "in", "io", "is", "it-ch", "it-it", "it", "iu", "iw", "ja", "ji", "jv", "jw", "ka", "kg", "ki", "kj", "kk", "kl", "km", "kn", "ko", "kok", "kr", "ks", "ku", "kv", "kw", "ky", "kz", "la", "lb", "lg", "li", "ln", "lo", "ls", "lt", "lu", "lv", "mg", "mh", "mi", "mk", "ml", "mn", "mo", "mr", "ms-bn", "ms-my", "ms", "mt", "my", "na", "nb", "nd", "ne", "ng", "nl-be", "nl-nl", "nl", "nn", "no", "nr", "ns", "nv", "ny", "oc", "oj", "om", "or", "os", "pa", "pi", "pl", "ps", "pt-br", "pt-pt", "pt", "qu-bo", "qu-ec", "qu-pe", "qu", "rm", "rn", "ro", "ru", "rw", "sa", "sb", "sc", "sd", "se-fi", "se-no", "se-se", "se", "sg", "sh", "si", "sk", "sl", "sm", "sn", "so", "sq", "sr-ba", "sr-sp", "sr", "ss", "st", "su", "sv-fi", "sv-se", "sv", "sw", "sx", "syr", "ta", "te", "tg", "th", "ti", "tk", "tl", "tn", "to", "tr", "ts", "tt", "tw", "ty", "ug", "uk", "ur", "us", "uz", "ve", "vi", "vo", "wa", "wo", "xh", "yi", "yo", "za", "zh-cn", "zh-hk", "zh-mo", "zh-sg", "zh-tw", "zh", "zu")dat<-dat|>llm_custom(comment_text, sys_prompt, "language", valid_resps =valid_responses)
! There were 3 predictions with invalid output, they were coerced to NA
Let’s see the results.
dat<-as_tibble(dat)# convert dat to tibble (optional)print(dat%>%select(language, comment_text))
# A tibble: 20 × 2
language comment_text
<chr> <chr>
1 en "YOU ARE SO CLOSE TO 10 MILLION!!!"
2 <NA> "\U0001f60d"
3 <NA> "Also watch https://youtu.be/7QkYTgDMpCs"
4 en "I❤️U \U0001f48b\U0001f48b\U0001f48b\U0001f48b\U0001f48b\U0001f48b\U…
5 es "Ya lo tengo y estoy escribiendo de acá del iPhone me anda de 10"
6 en "Amazing video I love the Bollywood touch in this video keep going …
7 en "Where's iPhone 9? Just skips to iPhone x. Lol okay nice math there…
8 ar "عملت قنات جديدة تختص في تقديم أنجح و أسهل وصفات الحلويات، تعالو شو…
9 en "Nothing new..\\nIphoneX is copy of essiential phone.\\nAndy Rubin …
10 en "Lol @22:46:09\\n\\nTim's kinda an ass"
11 en "3 years late on wireless charging, 3 years late on oled technology…
12 <NA> "https://youtu.be/Kp_DBWtS6SU"
13 en "I love your music videos their always great and inspiring!"
14 en "I like for Linsey. Love yours full themes. Great job."
15 en "I love that blond hair!!!!"
16 ja "黒髪もも可愛すぎ\U0001f60d\U0001f495\U0001f495"
17 ko "Sana is my damn bias wrecker, i swear. between her and Nayeon it's…
18 en "where is Steve Wozniak, fuck apple authority"
19 en "just one question, wtf?"
20 en "She is BEA-UTIFUL. And this showed a side I've never seen before. …
Nice, we have detected the languages of the comments. We can also see that some comments are tagged as NA. These are the comments that contain emojis, urls, or gibberish.
Sentiment Analysis
For the sentiment analysis we will use another Kaggle dataset. You can download it from my Google Drive here. The dataset contains Amazon product reviews. We will select random 20 comments and run a sentiment analysis on them.
Id ProductId UserId ProfileName
Min. : 1 Length:35173 Length:35173 Length:35173
1st Qu.: 8794 Class :character Class :character Class :character
Median :17587 Mode :character Mode :character Mode :character
Mean :17587
3rd Qu.:26380
Max. :35173
HelpfulnessNumerator HelpfulnessDenominator Score
Min. : 0.000 Min. : 0.000 Min. :1.000
1st Qu.: 0.000 1st Qu.: 0.000 1st Qu.:4.000
Median : 0.000 Median : 1.000 Median :5.000
Mean : 1.558 Mean : 2.002 Mean :4.156
3rd Qu.: 1.000 3rd Qu.: 2.000 3rd Qu.:5.000
Max. :203.000 Max. :219.000 Max. :5.000
NA's :1 NA's :1 NA's :1
Time Summary Text
Min. :9.617e+08 Length:35173 Length:35173
1st Qu.:1.268e+09 Class :character Class :character
Median :1.307e+09 Mode :character Mode :character
Mean :1.294e+09
3rd Qu.:1.330e+09
Max. :1.351e+09
NA's :1
Preparing the Data
The data actually contains a score column which is the rating of the product. We will select 4 random reviews for each score from 1 to 5 so that we can also test the LLM performance this time.
We can use llm_custom() function again with a well developed system prompt by ourselves. Yet, the package mall already contains a function for sentiment analysis called llm_sentiment(). Let’s try it out:
First, attach the model. Then run the sentiment analysis on the reviews. We will use the Text column as the target variable and comment_sentiment as the new column name for the sentiment analysis results.
# A tibble: 20 × 3
comment_sentiment Score Text
<chr> <int> <chr>
1 negative 1 "I have 2 chihuahua's and they are not at all intere…
2 negative 1 "I am sure that this coffee tastes good, but I am no…
3 negative 1 "I bought this gourmet popping corn believing I was …
4 negative 1 "I strongly suspect this caviar, which is widely ava…
5 negative 2 "I ordered this for my birthday. I got birthday mone…
6 negative 2 "I love raspberry and chocolate. I could live on Se…
7 negative 2 "As with most of the reviews here my tins arrived wi…
8 negative 2 "These dried strawberries do taste good - indeed, th…
9 negative 3 "It was my mistake - I thought there were 6 bags rat…
10 neutral 3 "I have been feeding Canidae for a long time, and wh…
11 negative 3 "I usually buy this at our local Whole Foods or Harr…
12 neutral 3 "This carbonated product has a nice natural juice ta…
13 negative 4 "If you read the first review and then read the comp…
14 positive 4 "This Wolfgang Puck coffee tasted great. The vanilla…
15 positive 4 "Being a peanut butter lover, have to keep it out of…
16 positive 4 "My dogs are bone lovers. These are a little messy …
17 positive 5 "Received ají amarillo in a well-wrapped box.…
18 positive 5 "This coffee is bold and strong, just how I like it.…
19 positive 5 "Having been on a gluten free diet for less than a y…
20 neutral 5 "I have to admit, when I saw this available on vine …
We can see that although our bot is mostly successful, there are some false negative (where the detected sentiment is negative while the score is 4 or 5) results. A larger model would be more successful in this task. Yet, there are no false positive results as all 1 and 2 scores are detected as negative. Naturally, we expect scores 3 to be neutral, but the comment might be more on the negative or positive side. So it is ok if the model detects a 3 as negative or positive rather than neutral.
Terminate the Ollama Session
Whatever the task is, after using a local LLM, it would be wise to terminate the session to free up the memory. You can do this by running the following command in the terminal.
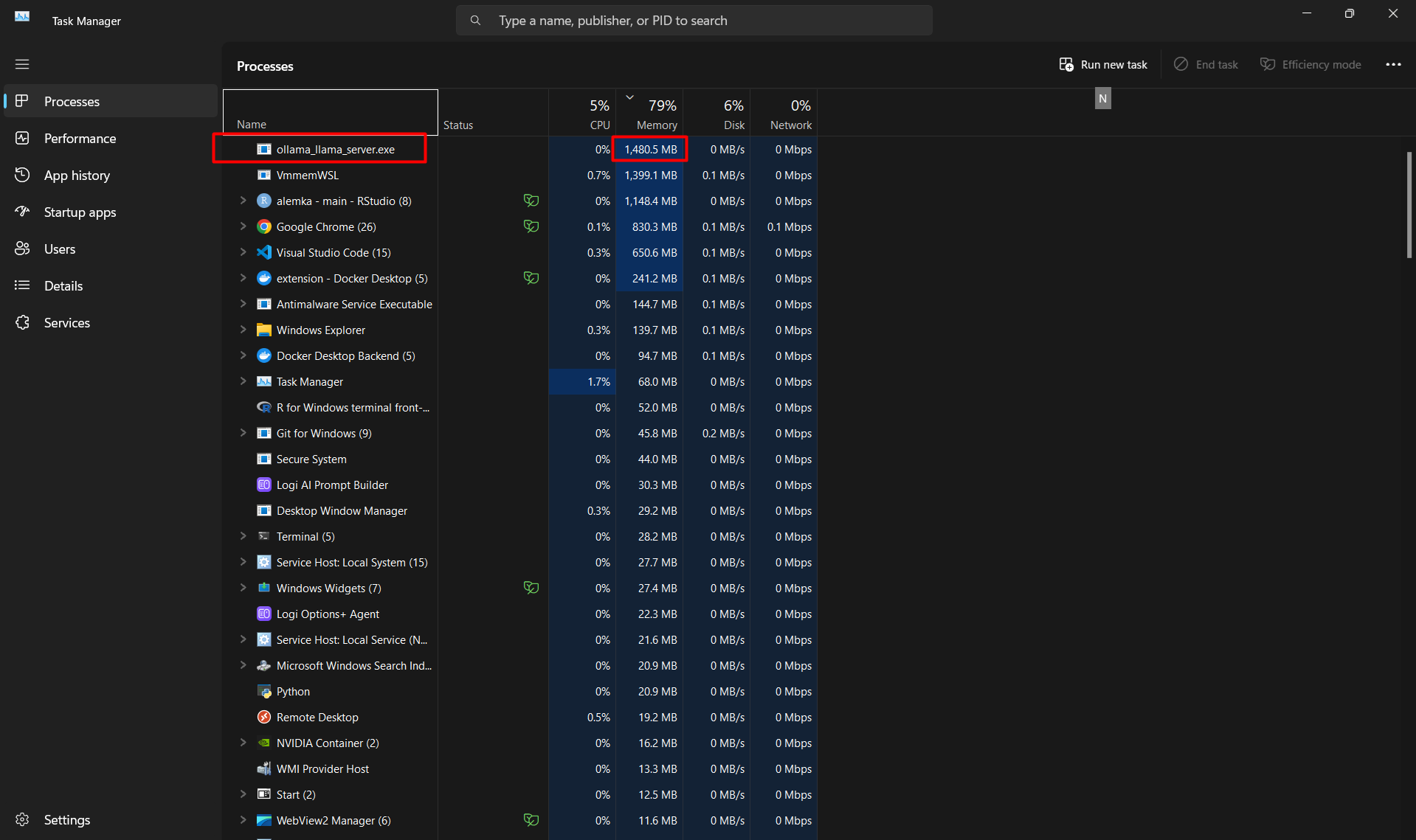
What I do to make sure that the session is terminated is to check the memory usage of the LLM on the Task Manager. Just press CTRL + ALT + DEL and select Task Manager on Windows. Then go to the Processes tab and order by Memory. You will see the memory usage of Ollama. If ollama is not in the list or its memory usage value is close to zero, then the session is terminated. See the screen shot before the termination below. The memory usage is up above of the list. After stopping the process, it was gone.
Conclusion
In this post, we discussed how to use a local LLM for language detection and sentiment analysis. Ollama services were used to install llama3.1:8b We used the mall package to interact with the LLM. We also discussed how to install the model and how to terminate the session on the terminal.
We have seen that the LLM is quite successful in detecting the languages of the comments or the sentiments of the reviews. An important final mark would be to remember that the larger the model, the better the accuracy. However, the larger the model, the more hardware you need. So, it is always a trade-off between accuracy and resources.