For the Best Experience - It is highly recommended browsing this blog on a desktop or laptop computer for the most optimized viewing experience. Enjoy exploring!
Exploratory Factor Analysis with Likert Scale Data
This post focuses on exploratory factor analysis on likert scale data using the conventional principal axis factoring. It also includes the calculation of ordinal alpha coefficient for the reliability of the scale. The analysis is supported with visuals.
dplyr
ggplot2
mirt
psych
Author
Affiliation
Ali Emre Karagül
TOBB ETU- University of Economics & Technology
Published
November 18, 2024
Mailchimp Subscription Modal
×
Introduction
EFA is used to identify a potentially lower number of unobservable factors or constructs that can explain the patterns of correlations within a set of observed variables. This technique is widely used in the development of tests and measurements in psychological, educational, and social sciences research to ensure that the test measures what it’s supposed to measure.
In this post, we will build an EFA model using a Likert scale data obtained from Open Psychometrics. Follow the link and find the zip file (OSRI44_dev_data.zip) containing data related to Open Sex Role Inventory. This is an interactive personality test measuring masculinity and femininity (or gendered personality traits) modeled on the Bem Sex-Role Inventory.
Likert scale data has multiple categories. Thus, it requires running the EFA with polychoric corelations. We will also utilize principle axis factoring. For the reliability of the scale, we will use ordinal Alpha coefficient suggested by Zumbo et al. (2007). All will be run using R. Unfortunately, software like SPSS do not provide an EFA with polychoric correlations or ordinal alpha coefficient. That’s why we have to use languages like R. Another alternative to SPSS in this regard is JASP (which is also built with R in terms of statistics) but it still doesn’t provide a way to calculate ordinal alpha.
Once you download the data, you will see two files in the folder: codebook.txt and data.csv. The first gives us information about the data, and the later contains the data itself. Move the data.csv to your working directory and run the following code to see the structure of the data.
data<-read.delim("data.csv")str(data[,40:57])# run str(data) to see all items. we do not include the first 39 items here
There are 57 variables and the first 44 variables are actual data collected from the questionaire while the rest contains information about the test taker.
To see the number of test takers, run the following:
The number of observations is 318573, which I find a little exhausting for a demo analysis. So I will filter it to reduce the number. These are some of the demographics of the participants:
engnat ” Is English you native language?” 1=Yes, 2=No
age “What is your age?”, entered as text (ages < 13 not recorded)
education “How much education have you completed?” 1=Less than high school, 2=High school, 3=University degree, 4=Graduate degree gender 1=Male, 2=Female, 3=Other
hand “What hand do you use to write with?” 1=Right, 2=Left, 3=Both
source how the user found the test, based on HTTP Referer info. 1=google, 2=tumblr, 3=facebook/messenger, 4=reddit, 5=bing, 0=other or unknown.
Let’s filter participants whose native language is English, who are right-handed, between ages 18 and 40, and came from Google. Also, only keep the questionaire data as we are not interested in the others from now on. Finally see the summary of the data:
Q1 Q2 Q3 Q4 Q5
Min. :0.000 Min. :0.00 Min. :0 Min. :0.000 Min. :0.000
1st Qu.:1.000 1st Qu.:2.00 1st Qu.:1 1st Qu.:2.000 1st Qu.:1.000
Median :1.000 Median :5.00 Median :3 Median :4.000 Median :3.000
Mean :2.023 Mean :3.76 Mean :3 Mean :3.281 Mean :2.972
3rd Qu.:3.000 3rd Qu.:5.00 3rd Qu.:5 3rd Qu.:5.000 3rd Qu.:4.000
Max. :5.000 Max. :5.00 Max. :5 Max. :5.000 Max. :5.000
Continuous variables: In our case the data is in likert scale, thus descrete. For such data, IRT based factor reduction is much more appropriate, which we will discuss in a later post. Yet, in practice, researchers use EFA with likert-scale data too if the scale is large enough.
No outliers: Outlier detection is another topic for another post. We will disregard this for now.
No multicollinearity: This is an assumption we can check simply with a correlation matrix. Basically, EFA expects no observed variables with high correlation. If there are pairs with high correlation, there are suggestions such as dropping one of the pair or merging them into a single variable.
Sampling Adequecy: We check if the data is adequate for EFA using Kaiser-Meyer-Olkin (KMO) test for each observed variable as well as the whole model. KMO values above .60 is considered acceptable, while closer to 1 means much better adequecy.
Sphericity: An assumption that is usually tested with Bartlett’s Test of Sphericity. The assumption here is that the correlation matrix cannot be an identity matrix (also referred as unit matrix). An identity matrix is a diagonal matrix with all its diagonal elements equal to 1 , and zeroes everywhere else. Bartlett’s test tests the null hypothesis that the correlation matrix is an identity matrix. If the p-value is less than .05, we reject the null hypothesis and conclude that the correlation matrix is not an identity matrix, which means the data is suitable for EFA.
In this post, we will test multicollinearity, KMO and Bartlett’s Test of Sphericity.
Multicollinearity
Let’s see a correlation heatmap for multicollinearity.
library(psych)library(plotly)poly_matrix<-polychoric(df)$rho# Create a long format of the correlation matrixpoly_long<-as.data.frame(as.table(poly_matrix))%>%filter(as.numeric(Var1)<=as.numeric(Var2))# Create the Plotly heatmapplot_ly( data =poly_long, x =~Var2, y =~Var1, z =~Freq, text =~round(Freq, 2), type ="heatmap", colorscale =list(c(0, "blue"), # Minimum correlation (-1)c(0.5, "white"), c(1, "red")# Maximum correlation (1)), zmin =-1, # Set the minimum value of the color bar zmax =1, # Set the maximum value of the color bar showscale =TRUE)%>%layout( xaxis =list(title ="Variables", tickangle =45), yaxis =list(title ="Variables"), title ="Correlation Matrix", colorbar =list(title ="Correlation", tickvals =c(-1, -0.5, 0, 0.5, 1))# Customize legend ticks)
Items with high correlation are candidates for merging or dropping. There are two cells with colors dark red or dark blue in the heatmap. Q21 and Q8 have negative high correlation (.77) and Q43 and Q27 has positive high correlation (.97). We can consider dropping one variable from each pair. Let’s see the values of these cells:
poly_matrix[8, 21]
[1] -0.7707296
poly_matrix[27, 43]
[1] 0.9671933
Removing one of the variables from each pair is a common practice in EFA. We will drop Q21 and Q43. Then, create the polychoric matrix again.
Now, let’s check the sampling adequacy with KMO test. We expect each varianle’s KMO value to be above .60. Also, the overall KMO value should be be above .60 too.
As, the assumptions we tested are fulfilled, we can continue with the
Determine the number of factors
While determining the number of factors to extract, there are many methods that can be used. See a summary of them in Zwick et.al. (1986). Some of the most common methods are:
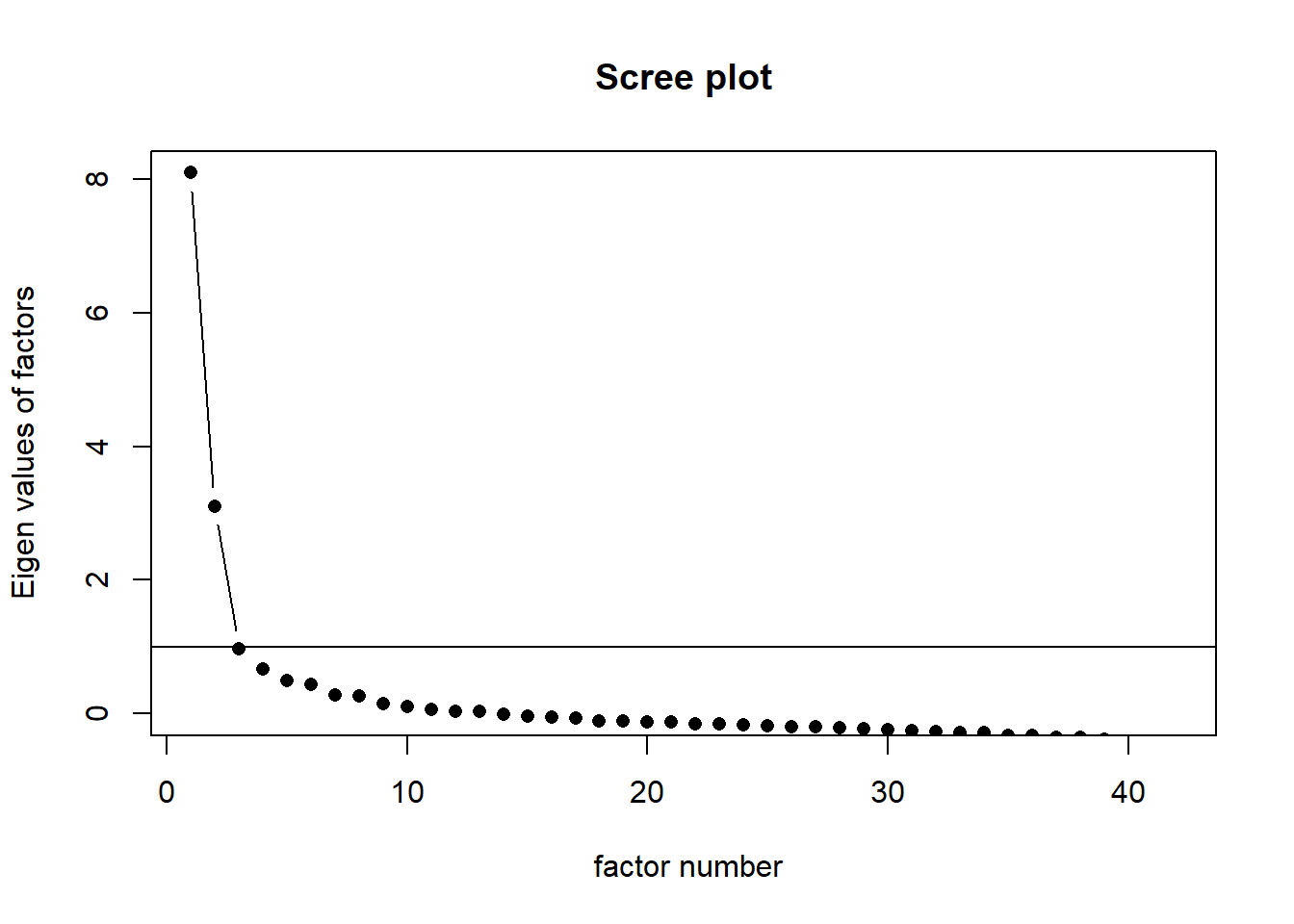
1. Kaiser Criterion (K1): we can use the Kaiser criterion, which suggests retaining factors with eigenvalues greater than 1.
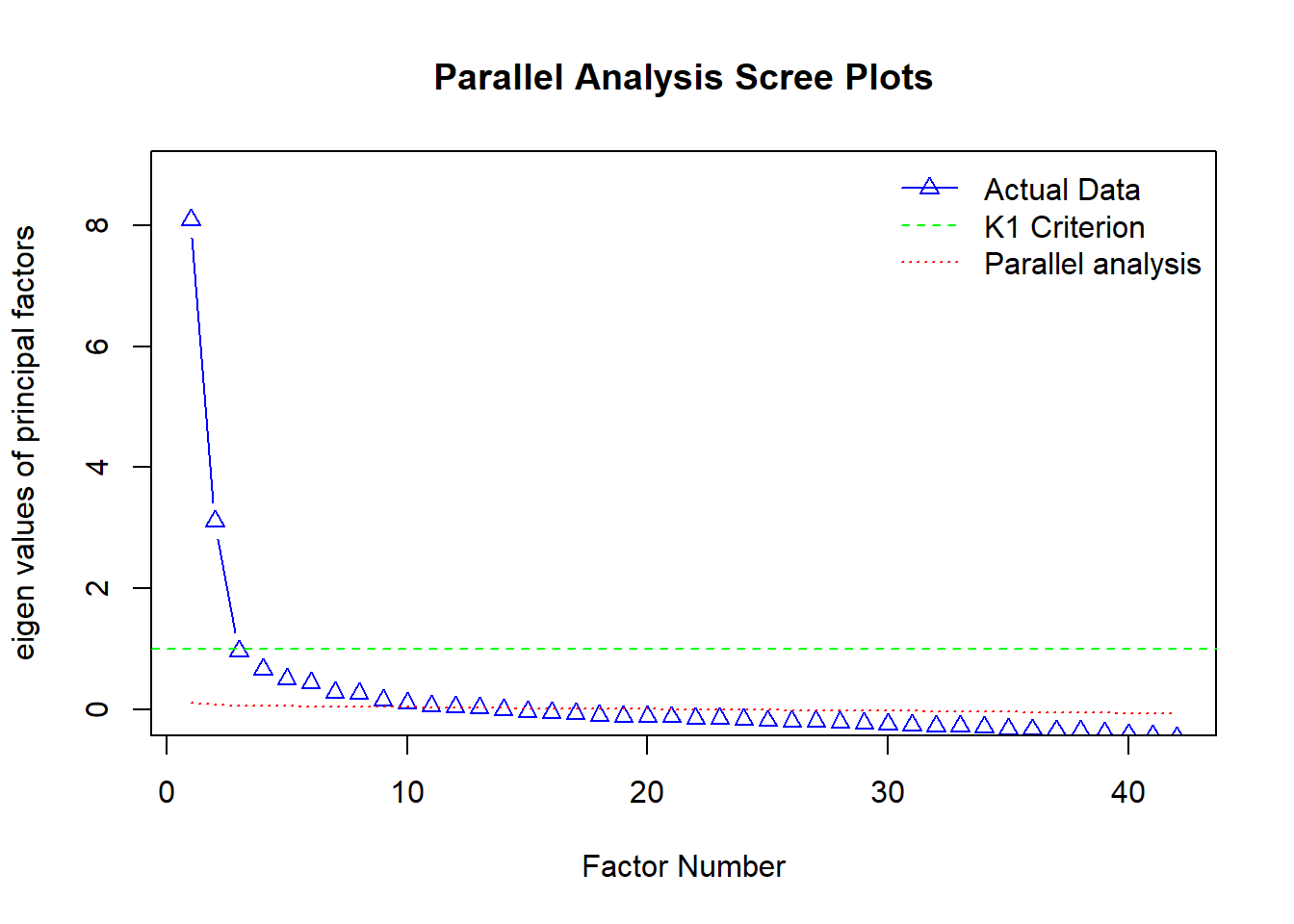
2. Paralell Analysis: This is a simulation-based method that compares the observed eigenvalues with the eigenvalues obtained from random data. The factors with eigenvalues greater than the random data are retained in this approach.
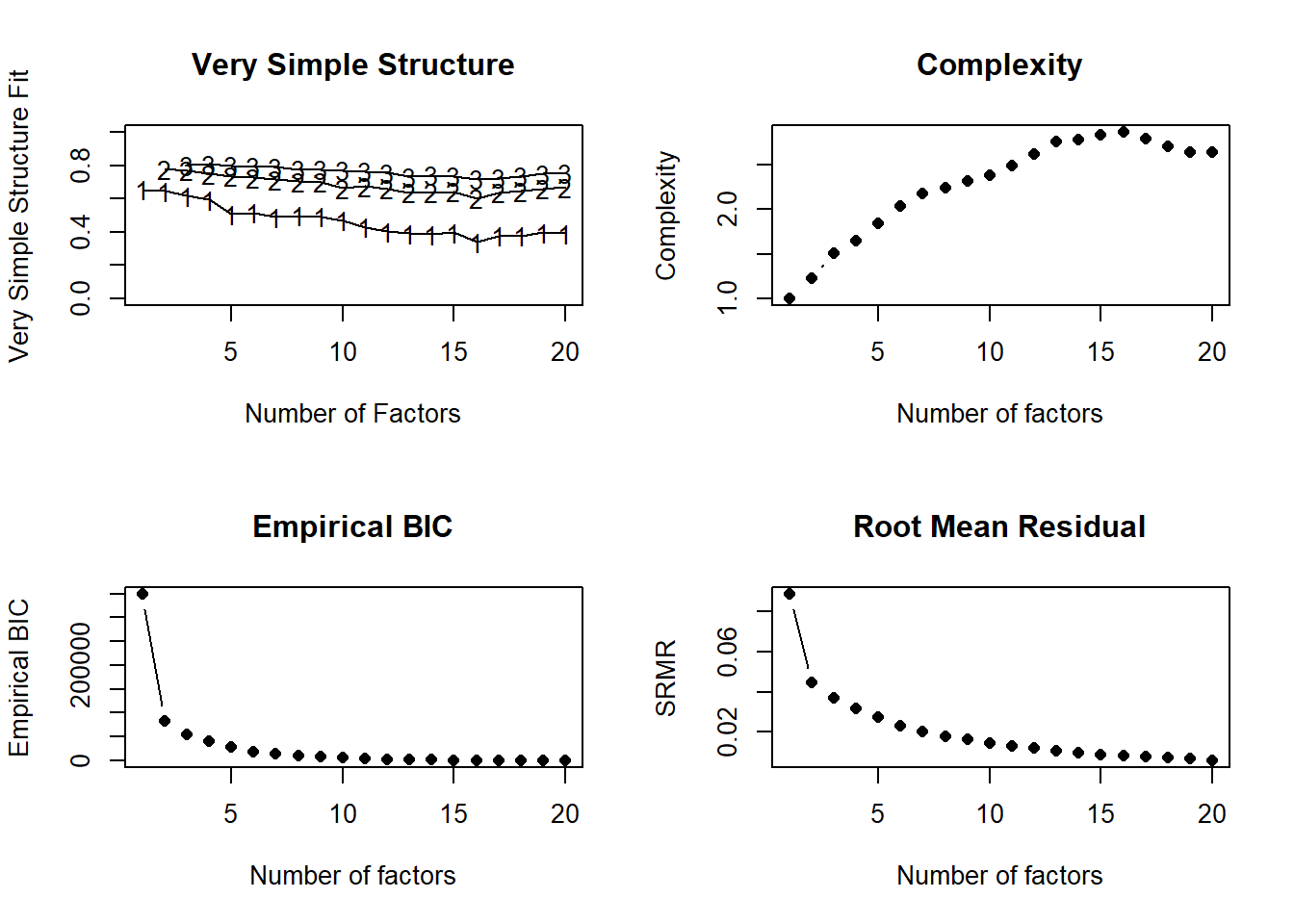
3. Very Simple Structure (VSS): VSS criterion evaluates how well a simplified factor pattern reproduces the original correlation matrix. In this simplified pattern, only the highest loading for each item is kept, while all other loadings are set to zero. The VSS score, ranging from 0 to 1, measures the goodness-of-fit of the factor solution. This evaluation is conducted for solutions with varying numbers of factors, starting from one (k = 1) up to a user-defined maximum. The optimal number of factors is determined by the solution with the highest VSS score.
4. Minimum Average Partial (MAP): This method is based on partial correlations matrix. It is very similar to Principal Component Analysis (PCA).
In order to implement Kaiser Criterion, we simply run the following code.
However, parallel analysis suggests 12 factors which is not reasonable. Let’s try VSS and MAP too. These can be obtained from nfactor() function of psych package.
vss_complexity<-nfactors(poly_matrix, n.obs =nrow(df), fm ="pa", cor ="poly", SMC=FALSE)
The output actually speaks for itself. To better understand this, let’s have a look at the plots produced with the function. The plot on the upper left corner shows the VSS fit values with the number of factors. As can be seen 2 and 3 factors are very close and they are higher than 1 factor. This is in alignment with the K1 criterion.
The plot on the upper right corner shows the complexity of the construct with the number of factors. Complexity increases as the number of factors increase until 12 factors. We do not want to go with a high number of factors, so this plot also supports our decision to ignore parallel analysis too.
The plot on the lower left corner shows the Empirical BIC values with the number of factors. BIC value decreases highest from 1 to 2 factors. But from 2 to 3, the decrease is not so eye-catching.
As for the plot on the lower right corner, it shows the RMR values with the number of factors. RMRs below 0.10 is acceptable while below 0.08 is desirable. Any model that has more than 1 factor has RMR below 0.08 in the plot.
In conclusion, we can say that 2 or 3 factors are reasonable, while the first is a little more preferable. For our final decision, we can also check the variance explained by two models. If there is not much increase from 2-factor model to 3-factor model, we can go with 2 factors.
two_fm<-fa(poly_matrix, n.obs =nrow(df), nfactors =2, fm ="pa", rotate ="none", cor ="poly", SMC=FALSE)three_fm<-fa(poly_matrix, n.obs =nrow(df), nfactors =3, fm ="pa", rotate ="none", cor ="poly", SMC=FALSE)#Explained Variance by 2-Factor Model:two_fm$Vaccounted
PA1 PA2
SS loadings 8.1762800 3.2680913
Proportion Var 0.1946733 0.0778117
Cumulative Var 0.1946733 0.2724850
Proportion Explained 0.7144368 0.2855632
Cumulative Proportion 0.7144368 1.0000000
#Explained Variance by 3-Factor Model:three_fm$Vaccounted
PA1 PA2 PA3
SS loadings 8.1985977 3.2818970 1.08421360
Proportion Var 0.1952047 0.0781404 0.02581461
Cumulative Var 0.1952047 0.2733451 0.29915972
Proportion Explained 0.6525100 0.2611996 0.08629039
Cumulative Proportion 0.6525100 0.9137096 1.00000000
The variance explained cumulatively by the 2-factor model is 0.27 while the 3-factor model explains 0.30. The increase is not so high, so we can go with the 2-factor model.
Rotation
To see if we need to rotate, we can check the factor loadings. If the loadings are high and clear, we can go without rotation. Let’s see the loadings for the 2-factor model.
factor_loadings<-two_fm$loadingsprint(head(factor_loadings))#use the following for all variables: print(factor_loadings)
The loadings are not so clear. Some of the observed variables load on both factors highly and equally such as Q3, Q4, Q5 etc. We can try to rotate the factors.
Rotation does not change the underlying solution but redistributes the variance to simplify the interpretation of factor loadings.
It is typically used when you expect that each variable primarily loads on one factor, and you want to make those relationships clearer.
Rotation is a technique used to simplify the factor structure. It is used to make the factors more interpretable. There are two types of rotation: orthogonal and oblique. Orthogonal rotation assumes that the factors are uncorrelated, while oblique rotation allows the factors to be correlated.
In contemporary research, oblique rotation is more commonly used, particularly in fields like psychology, sociology, and behavioral sciences, where correlated factors are expected. While orthogonal rotation is still used in cases where independence among factors is assumed or desired, the realistic nature of oblique rotations makes them the preferred choice for most exploratory factor analysis (EFA) applications.
There are many rotation methods such as varimax, promax, oblimin, and quartimin.
The loadings are now more clear. Also, we can see that some of the variables load neither of the variables. This is a common situation in EFA. This also explains why a 3-factor model is also strong. Yet, we prefer 2-factor model so We can drop these variables one by one and re-run the analysis. To determine with which item to start, we can check the communalities of the variables.
factor_1<-as.matrix(two_fm$loadings[,"PA1"])factor_2<-as.matrix(two_fm$loadings[,"PA2"])communalities<-two_fm$communality# merge as a tableloadings<-data.frame( factor_1 =factor_1, factor_2 =factor_2, communalities =communalities)loadings<-loadings[order(loadings$communalities, decreasing =FALSE),]print(head(loadings, 10))# use print(loadings) to see all variables
In EFA, we do not want communalities lower than .30. Also loadings lower than .30 are not considered as strong. Preferably, loadings above .40 are considered strong.
Dropping variables is an iterative practice. You need to drop one variable, re-run the analysis, check the loadings and communalities, and decide if you need to drop another variable. This process continues until all variables have strong loadings and communalities. Thus, I will report only the final solution here.
Following line of code will drop all the unwanted variables, and then re-run the 2-factor model with oblimin rotation:
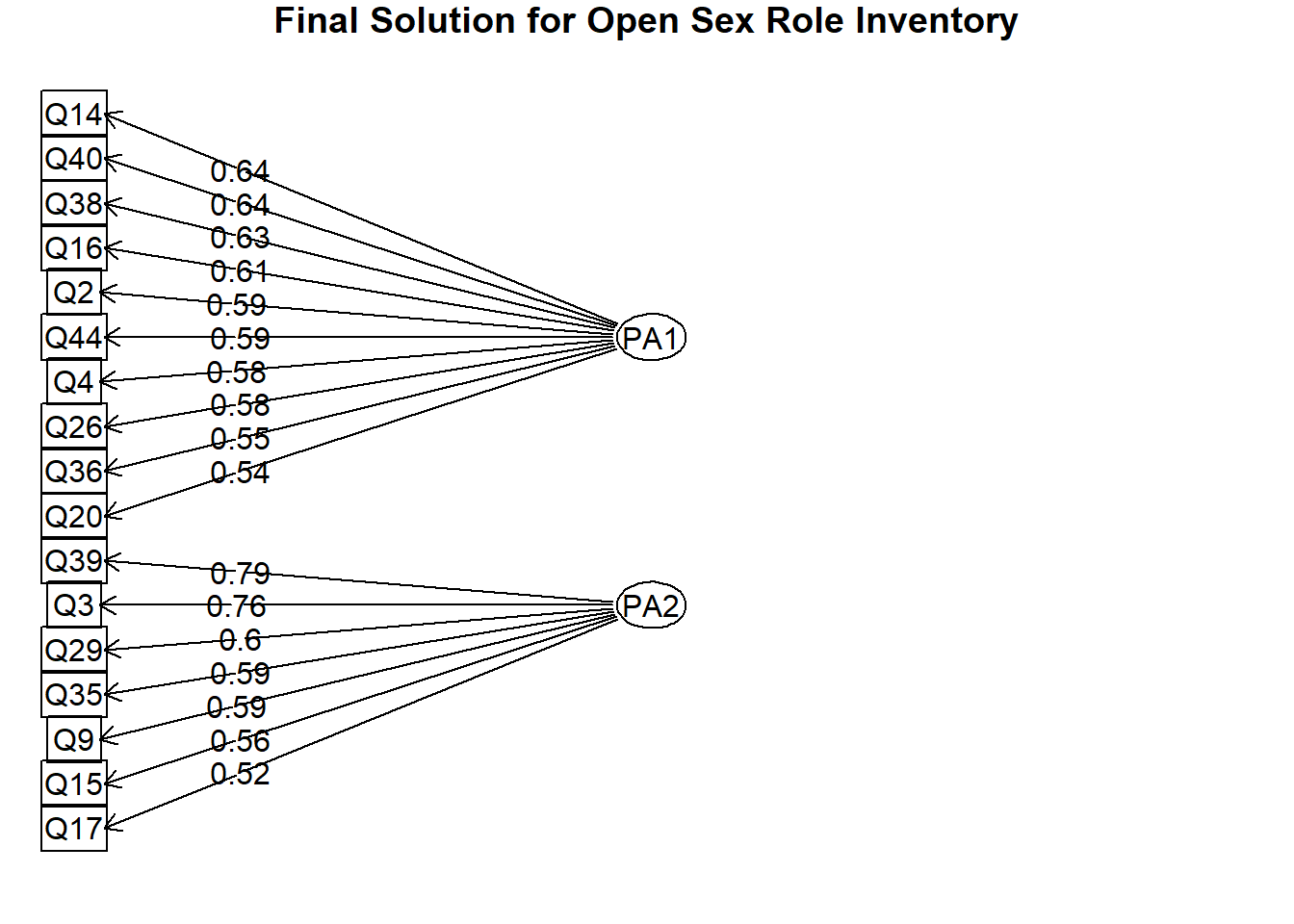
Correlation between factors is -0.24, which indicates a very low and negative correlation. The ordinal alpha coefficient is 0.84 which is considered as good. The 2-factor model with oblimin rotation is our final solution. Finally let’s draw the path diagram of the model:
fa.diagram(two_fm, digits =2, main ="Final Solution for Open Sex Role Inventory", e.size=.07, rsize=.1, cex=0.9)
The final solution has 10 items in the first factor and 7 items in the second factor. Here are the items in each factor:
Factor 1
Factor 2
Q2 I have thought about dying my hair.
Q3 I have thrown knives, axes or other sharp things.
Q4 I give people handmade gifts.
Q9 I like guns.
Q14 I dance when I am alone.
Q15 I have thought it would be exciting to be an outlaw.
Q16 When I was a child, I put on fake concerts and plays with my friends.
Q17 I have considered joining the military.
Q20 I sometimes feel like crying when I get angry.
Q29 I have burned things up with a magnifying glass.
Q26 I jump up and down in excitement sometimes.
Q35 I have taken apart machines just to see how they work.
Q36 I take lots of pictures of my activities.
Q39 I have set fuels, aerosols or other chemicals on fire, just for fun.
Q38 I leave nice notes for people now and then.
Q40 I really like dancing.
Q44 I decorate my things (e.g. stickers on laptop).
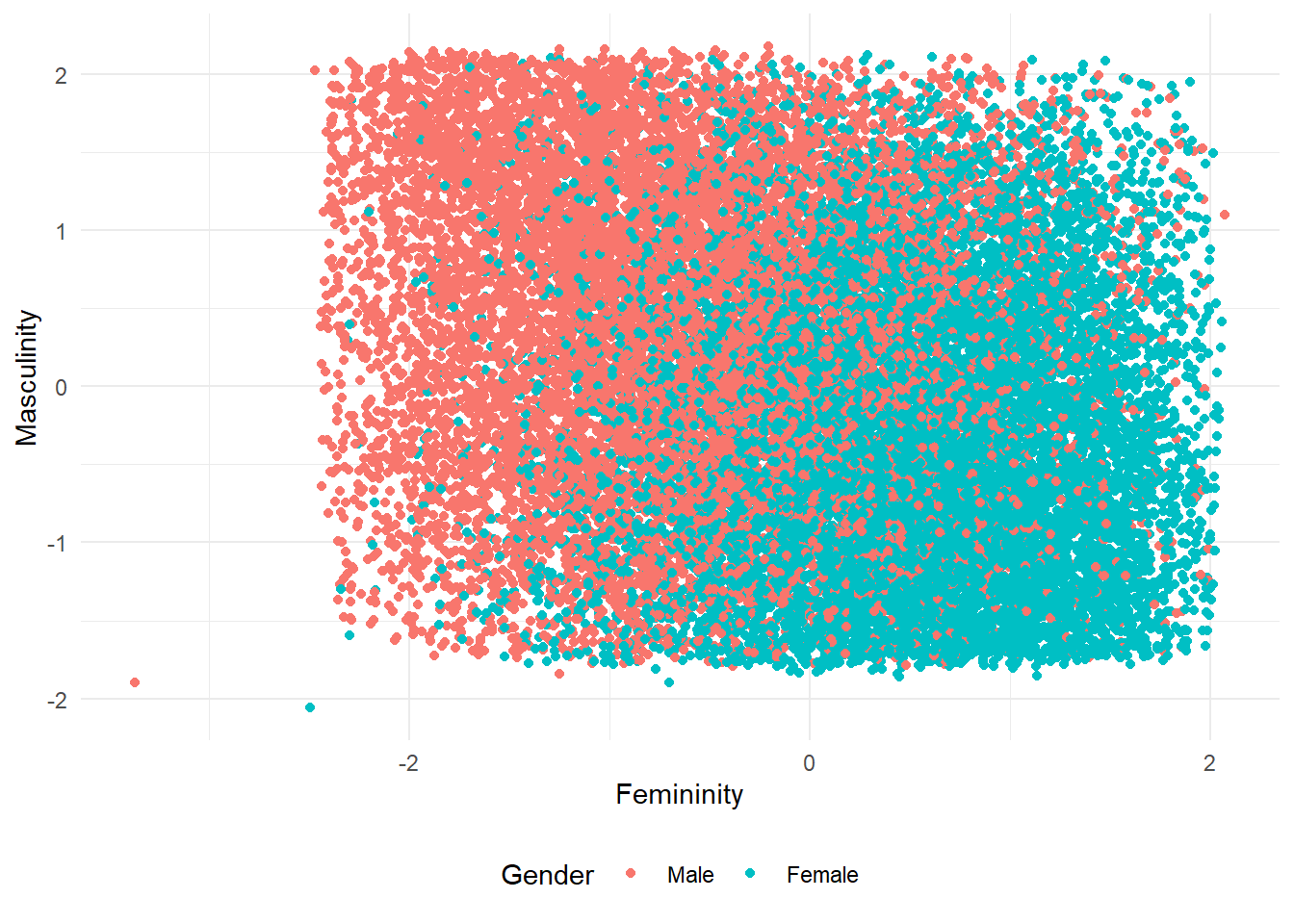
It is pretty easy now to interpret the factors given that this is a scale named as Open Sex Role Inventory. The first factor seems to be related to femininity while the second factor seems to be related to masculinity.
As a final touch, let’s see the scree plot of the genders of the participants along with their scores on the two factors; masculinity and femininity. We will use factor.scores() to calculate participants’ scores and the ggplot2 package for visualization:
In this post, we have seen how to conduct an EFA with polychoric correlations and ordinal alpha coefficient. We have also seen how to check the assumptions of EFA, determine the number of factors, and rotate the factors. We have also seen how to drop variables iteratively to reach a final solution. Then, we have seen how to interpret the factors and draw the path diagram of the model. Finally, we have seen how to obtain and visualize the scores of the participants on the factors.
Further Remarks
The data used here is a likert scale data. Yet, EFA actually expects continuous variables. Therefore, it might be wiser to use IRT based factor reduction methods for likert scale data. We will discuss this in a later post.
The outliers should be checked and removed before running the EFA. Yet, we haven’t done it here. Outlier detection is another topic for another post.